
XPMEM-based Hierarchical Collectives (XHC)
Collective operations are widely used by MPI applications to implement their communication patterns. Efficiency of these operations is crucial for both performance and scalability of parallel applications. For deriving efficient MPI implementations, significant effort is put to keep pace with advances and capabilities of the underlying compute hardware and interconnects. Recent processor advances have led to nodes with higher core counts and complex internal structures and memory hierarchies. Such nodes are able to host tens to hundreds of processes and thus, performance of MPI collectives at the intra-node level becomes critical.
The XHC (XPMEM-based Hierarchical Collectives) software component implements optimized intra-node MPI collectives in Open MPI, especially considering nodes with high core counts and complex memory topologies. It is actively developed by FORTH in the context of DEEP-SEA, and currently supports the Broadcast, Barrier and Allreduce primitives, with support for more operations planned (e.g. Reduce and Gather).
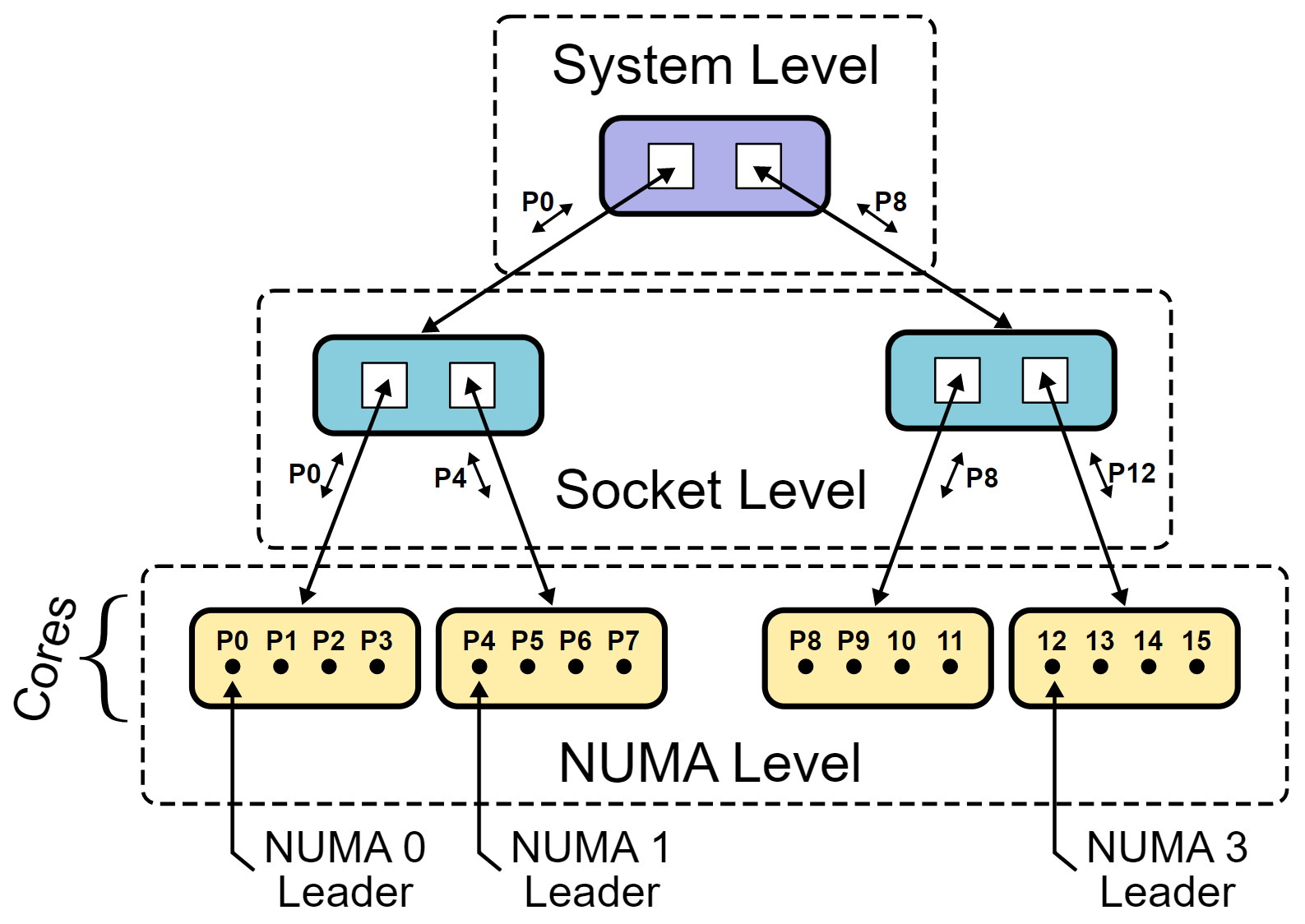
The XHC implementation [1] combines the low latency of the shared-memory transport technique for small messages with the benefits of single-copy transfers through the XPMEM (Cross-Partition Memory) Linux kernel module for larger ones. The algorithms’ communication pattern follows a configurable n-level hierarchy, that dynamically discovers and adapts to the system’s internal structure (e.g. NUMA regions, CPU sockets, cache hierarchies). The majority of communication takes place between nearby processes inside these topological features, limiting the need to transfer data to remote nodes. This helps avoid memory congestion and better distributes the load across the cores in the node. Pipelining enables overlapping communications across all levels of the hierarchy. Finally, synchronization is handled explicitly inside XHC, following the single-writer-multiple-readers paradigm, thus avoiding the overheads of atomic operations or shared memory locks.
As shown in Figure 1, Cores/processes are grouped according to their NUMA locality, and then according to their CPU socket locality. One process on each group is elected the leader, and the leaders communicate amongst them on the next level — the pattern repeats to the top of the hierarchy. Work to integrate XHC with OpenMPI’s HAN (Hierarchical AutotuNed) framework is ongoing in DEEP-SEA, to allow the performance benefits inside the node to extend to multi-node computing systems. FORTH continues exploring new research avenues, e.g. consideration of additional processor architectures, and further performance optimizations.
References
- G. Katevenis, M. Ploumidis and M. Marazakis, “A framework for hierarchical single-copy MPI collectives on multicore nodes,” 2022 IEEE International Conference on Cluster Computing (CLUSTER), 2022, doi: 10.1109/CLUSTER51413.2022.00024.