DEEP-SEA tackles multiple parallel programming interfaces, including the most commonly used (MPI, OpenMP) as well as alternative approaches (such as PGAS-based libraries), up to Domain Specific Languages (DSLs).

Programming Enviroments
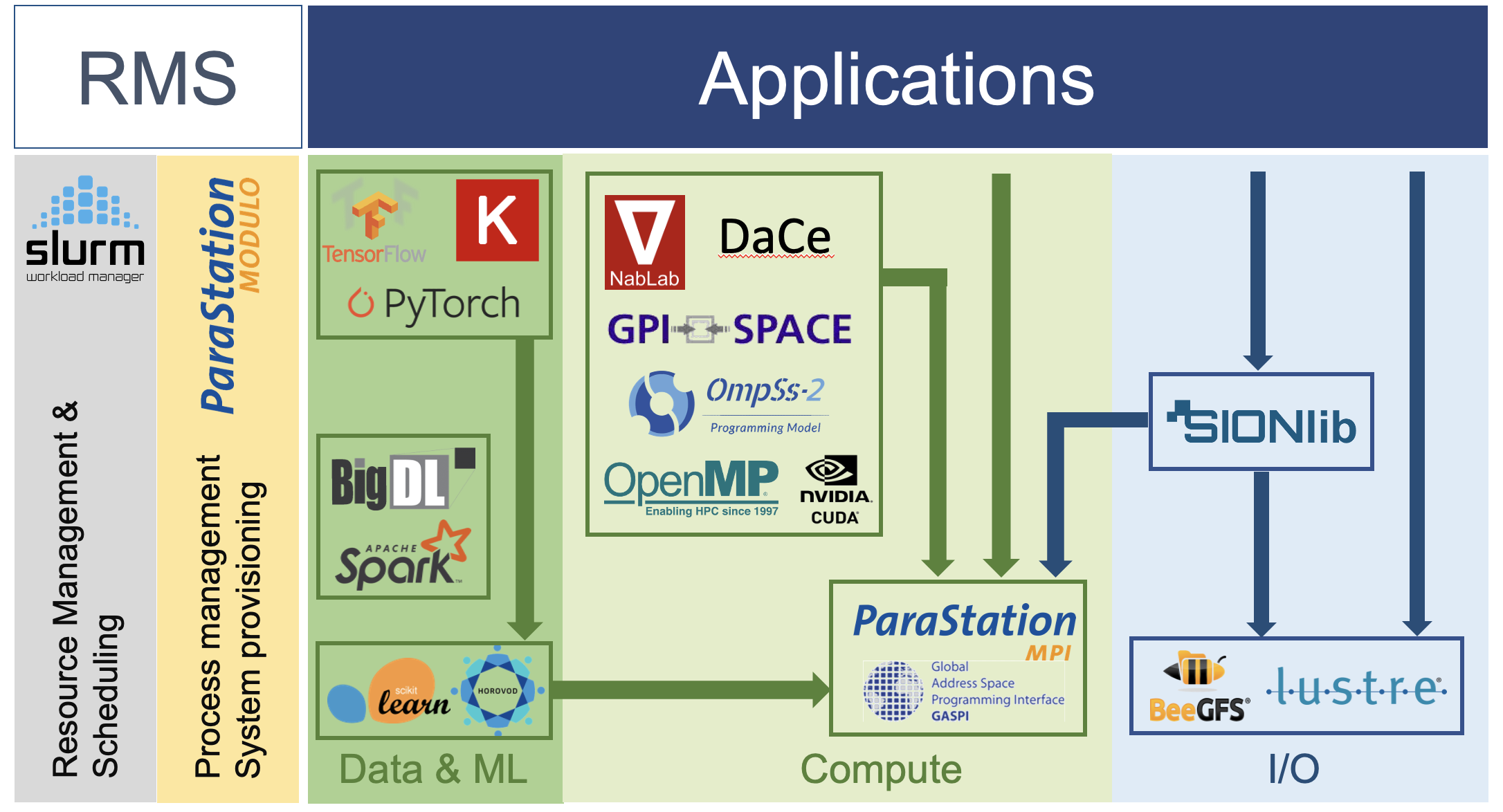
Driven by co-design, DEEP-SEA aims at shaping the programming environment for the next generation of supercomputers, and specifically for the Modular Supercomputing Architecture (MSA). To achieve this goal, all levels of the programming environment are considered: from programming languages and APIs to runtime interaction with HW resources.

ParaStation MPI
A central pillar of the software stack in the DEEP projects is ParaStation MPI, an MSA-enabled implementation of the Message-Passing Interface (MPI) standard.
GPI-2
GPI-2 is an API for the development of scalable, asynchronous, and fault tolerant parallel applications. GPI-2 implements the GASPI specification, an API specification for asynchronous communication which leverages remote completion and one-sided RDMA-driven communication in a PGAS. GASPI is maintained by the GASPI Forum with the aim of having a specification as a reliable, scalable, and universal tool for the HPC community.
GPI- SPACE
GPI-Space is a task-based workflow management system for parallel applications. GPI-Space is designed on the principle of separation between the automatic management of parallel executions and the description of the problem-specific computational tasks and their interdependencies.
SIONlib
SIONlib is a library for writing and reading data from many thousands of parallel tasks/processes into or from one or a small number of physical files. Only the file open and close functions are collective, while each task or process can access files independently.
ECOHMEM
Hybrid memory systems are an emerging trend to provide applications with larger random access memory (RAM) at reasonable cost and energy consumption. Byte-addressable persistent memory (PMEM) technology offers better latency than NAND technologies (e.g. SSD devices) and higher capacity than DRAMs. They are attractive for applications using huge memory volumes, and create the need for optimising application performance. Within the DEEP projects, we developed the ecoHMEM framework which exploits the different capabilities of the underlying memory infrastructure for performance optimisations without making any modifications to the application code.
OmpSs-2
The MSA architecture provides unprecedented flexibility, efficiency and performance by combining modules with different characteristics. Moreover, some modules can also be heterogeneous, combining different computing, memory and network devices on the same node.
OmpSs-2@Cluster
OmpSs-2@Cluster extends OmpSs-2 [1] to support transparent task offloading for execution on other nodes. Any OmpSs-2 program with a full specification of task dependencies is compatible with OmpSs-2@Cluster.
Dynamic Load Balancing (DLB)
DLB optimises the performance of hybrid (MPI & OpenMP/OmpSs) parallel applications and maximises their utilization of computational resources. It is a dynamic library transparent to the user and does not require any modifications of the application code.
MSA Extensions
ParaStation MPI makes affinity information available to applications running across different modules of the DEEP system while adhering to the MPI interface. This way, applications can exploit the underlying hardware topology for further optimisations while maintaining portability across systems. These optimisations are not limited to the program flow but may likewise affect the communication patterns. For example, by using the new split type MPIX_COMM_TYPE_MODULE, applications are able to create module-specific MPI communicators.
Additionally, ParaStation MPI itself applies application-transparent optimisations for modular systems, in particular regarding collective communication patterns. Based on topology information, collective operations such as Broadcast or Reduce are performed hierarchically so that the inter-module communication (forming a potential bottleneck) is reduced.
As part of DEEP-SEA, further MSA-driven enhancements to ParaStation MPI will be made towards a generalisation of its hierarchy awareness to arbitrary hierarchy levels such as NUMA domains, nodes, interconnects, or (sub-)modules. These enhancements will have the ability to consider different information and information sources (hwloc, PMIx, environment variables, and others) and will add MSA awareness also within MPICH’s Collectives Selection framework (Csel) as well as MSA awareness based on Process Sets (psets) in the MPI Sessions context, with psets for reflecting module affinity, for instance.
Malleability Support
Malleability in HPC in general and malleable runtime environments in particular are key innovation areas of DEEP-SEA. In this context, ParaStation MPI will be adapted to enable dynamic resource changes of MPI applications. Such resource changes can be either requested by the application (active malleability) itself or induced by the resource management system (passive malleability). The DEEP-SEA project envisions a malleability solution on the application side that is based on the MPI Sessions concept introduced with MPI-4. ParaStation MPI will support MPI Sessions so that applications can use them to detect and apply resource changes. Basic support for the Process Management Interface for Exascale (PMIx) standard is already available in the current ParaStation MPI release. The PMIx standard will serve as the interface between the node-local resource management and ParaStation MPI to manage resource changes. In particular, new Process Sets provided by the node-local resource management system (PMIx Server) upon resource changes will be managed by ParaStation MPI (PMIx clients). The set-up of connections to newly arriving processes and tear-down of connections to processes leaving will be hidden behind MPI Sessions and optimized as much as possible and reasonable. All advancements in ParaStation MPI with respect to malleability are done in close collaboration with the work done on malleable resource management and scheduling in the DEEP-SEA project. ParaStation MPI’s malleability features are tightly integrated with ParaStation Management, the Process Manager (PM) of ParaStation Modulo used by the DEEP system, as well as the DEEP-SEA Slurm malleability plugins for node scheduling, so that consistency of the DEEP-SEA malleability solution is ensured.
Containerisation
The current release of ParaStation MPI is PMIx-enabled (see also Malleability Section) and its interplay with the ParaStation Management resource management system via PMIx has been successfully tested on various production systems. This is the foundation on which users of the DEEP system may start their MPI applications in containers — however they still have to deal with the particularities of the respective container environment. To ease the use of MPI applications in containers, DEEP-SEA will support the Slurm container start-up mechanism (including Singularity) in the ParaStation Management resource management system, specifically in the ParaStation Slurm plugin for ParaStation Management (psslurm).
CUDA Awareness
By using a CUDA-aware MPI implementation, mixed CUDA & MPI applications are allowed to pass pointers to CUDA buffers located on the GPU to MPI functions, avoiding the need to copy data to/from non-CUDA memory. In contrast, a non-CUDA-aware MPI library would fail in such a case. Furthermore, a CUDA-aware MPI library may determine that a pointer references a GPU buffer to apply appropriate optimisations regarding the communication. For example, so-called GPUDirect capabilities can then be used to enable direct RDMA transfers to and from GPU memory. ParaStation MPI supports CUDA awareness, e.g., for the DEEP system ESB module, at different levels. On the one hand, the usage of GPU pointers for MPI functions is supported. On the other hand, if an interconnect technology provides features such as GPUDirect, ParaStation MPI is able to bypass its own mechanism for the handling of GPU pointers and to forward the required information to the lower software layers for the exploitation of such hardware capabilities.
Gateway Support
The MSA concept considers the support for different network technologies within distinct modules. Therefore, ParaStation MPI provides means for message forwarding based on so-called gateway daemons. These daemons run on dedicated gateway nodes being directly connected to different networks of an MSA system. This gateway mechanism is transparent to the MPI processes, i.e., they see a common MPI_COMM_WORLD communicator spanning the whole MSA system. Therefore, the mechanism introduces a new connection type: the gateway connection as compared with the fabric-native transports such as InfiniBand and shared-memory. These virtual gateway connections map onto the underlying physical connections to and from the gateway daemons. Transparency to the MPI layer is enabled by completely implementing the gateway logic on the lower pscom layer, i.e., the high-performance point-to-point communication layer of ParaStation MPI. This way, more complex communication patterns implemented on top, e.g., collective communication operations, can be executed across different modules offhand. ParaStation MPI takes different measures for the avoidance of bottlenecks with respect to the transmission bandwidth of the cross-gateway communication. For one thing, the module interface might comprise multiple gateway nodes. Therefore, the MPI bridging framework is able to handle multiple gateway nodes such that a transparent load balancing can be achieved among them on the basis of a static routing scheme. For another thing, the upper MPICH layer of ParaStation MPI is able to retrieve topology information (cf. MSA extensions) for the optimisation of complex communication patterns, e.g., to minimise the inter-module traffic. The gateway protocol supports both Eager and Rendezvous semantics. The latter avoids intermediate memory copies of large messages to pre-allocated communication buffers, but simply announces the MPI message by a small control message. Subsequently, the actual data transfer can be conducted efficiently by relying on the Remote Direct Memory Access (RDMA) capabilities of the hardware, avoiding the costly CPU involvements. Moreover, by relying on this approach, the message transfer may be delayed until the actual receive buffer is known to the communication layer, i.e., this is the case when the receive call has been posted by the application layer, enabling a direct payload transfer from the sender into this buffer without intermediate copies.
for further reading
Downloads
Para Station MPI
Para Station Github